8 min read
Competitive intelligence, business development, and indication selection, are being rebuilt around AI.

Strategic decision-making in biopharma hinges on bets made years before a molecule reaches a patient, which significantly determine the economics of R&D:
Competitive intelligence: what markets are worth pursuing?
Indication selection: where is our biology most likely to win?
Asset selection: what should we build, buy, or license?
Each is a capital allocation question with opposing failure modes: a company could mistakenly commit anywhere from $500 million to $2 billion toward a candidate that fails scientifically or commercially; it can also miss a viable asset because the best opportunity was in a different indication, or because the molecule was abandoned when its sponsor shut down. But making those calls has historically required teams to piece together fragmented information from SEC filings, ClinicalTrials.gov, conference presentations, Excel-based portfolio models, and go/no-go reports, manually assembled over weeks from numerous internal and external sources. The information was almost always stale by the time it reached the decision-maker, and the analysis was always bounded by the bandwidth of the team that produced it.
The constraints of this manual workflow have become more punishing as the biotech industry has become intensely competitive. Target crowding has accelerated, with parallel programs piling into the same mechanisms (GLP-1s in obesity, PD-1/VEGF in NSCLC, CD3xCD20 bispecifics in NHL, AAV gene therapies in narrow rare-disease indications, etc). Meanwhile, Chinese biotechs have rapidly shown themselves capable of developing credible best-in-class therapies on shorter timelines and lower COGS, accounting for 32% of global biotech out-licensing deal value in Q1 2025, up from 21% in both 2023 and 2024. And while pharma's reliance on external sourcing is not new (McKinsey reported in 2010 that over half of late-stage pipeline compounds were already externally sourced), this dependency has only increased over the past decade: more than 70% of new molecule revenue since 2018 has come from externally sourced products. As external partnerships and acquisitions become the dominant pipeline strategy in a more crowded field, biotechs need an all the more dynamic competitive picture to credibly position assets for partnership or acquisition.
Competitive Intelligence (CI): What markets are worth pursuing?
Competitive intelligence in biopharma has traditionally been a reactive job. Pre-AI, a mid-size biotech CI analyst would spend hours scanning trial registries like ClinicalTrials.gov and EU CTR, earnings call transcripts, new patent filings, press releases, and conference posters, then distill relevant findings for their higher-ups.
By the time their memo lands in the hands of a VP of Strategy or Chief Business Officer, it’s already old and incomplete: a static snapshot of a rapidly evolving landscape. This is especially true in fast moving indications such as GLP-1 agonists in obesity, bispecifics in oncology, and gene therapies in rare disease. Agents can now continuously monitor the same sources a human analyst would scan, but across the entire competitive landscape rather than a handful of priority programs, and surface relevant developments as they happen rather than in periodic review cycles.
Clarivate represents the incumbent approach in this market. Through its Cortellis and DRG platforms, Clarivate has long been a dominant provider of competitive intelligence data to the pharmaceutical industry through its pipeline databases, patent analytics, deal intelligence, and regulatory tracking. The company has been integrating AI across these products, adding NLP-based summarization, automated alert systems, and predictive analytics on top of its proprietary datasets; its Cortellis Drug Timeline & Success Rates tool trained on more than 22 years of curated pipeline data forecasts phase-by-phase probabilities of success and likely launch dates with region-specific outputs across the US, EU, Japan, China, Singapore, and South Korea.
But in February 2026, Clarivate announced it was pursuing a sale of its entire Life Sciences and Healthcare segment, which generated $389.8 million in revenue in 2025, down 6.9% year over year. Clarivate's stated rationale is to focus on its core Academia and Government and Intellectual Property businesses and use proceeds to reduce its $4.5 billion debt load. The timing is notable: a first-wave data incumbent is exiting just as AI-native entrants in the biopharma arena are reducing the value of curated databases by delivering competitive intelligence faster, cheaper, and more contextually, building reasoning and automation on top of public data rather than paywalled databases. In the second-wave era of CI software, it remains to be seen whether owning data is a sufficient moat when AI-native competitors can not only recreate comparable data sets cheaply but also layer reasoning, workflow automation, and decision support on top.
Founded by Alex Telford, Maged Ahmed, and Vikas Velagapudi, Convoke raised $8.6 million to develop “an autonomous workforce for the biopharma industry.” While the company aims to automate several workflows, its CI capabilities center on its ability to ingest and structure information from a wide range of sources, synthesizing internal files, proprietary databases, and external research into a continuously updating workspace; users can upload PDFs, PowerPoints, and scientific papers while Convoke pulls from APIs as well as its own proprietary structured datasets, including clinical-trial outcomes, competitor drug statuses, and indications. For CI specifically, teams can “set up trackers and automatic alerts to monitor new trials, data drops, and key events.” Unlike software of the prior wave, the competitive intelligence brief generated by Convoke becomes a living, continuously updated resource.
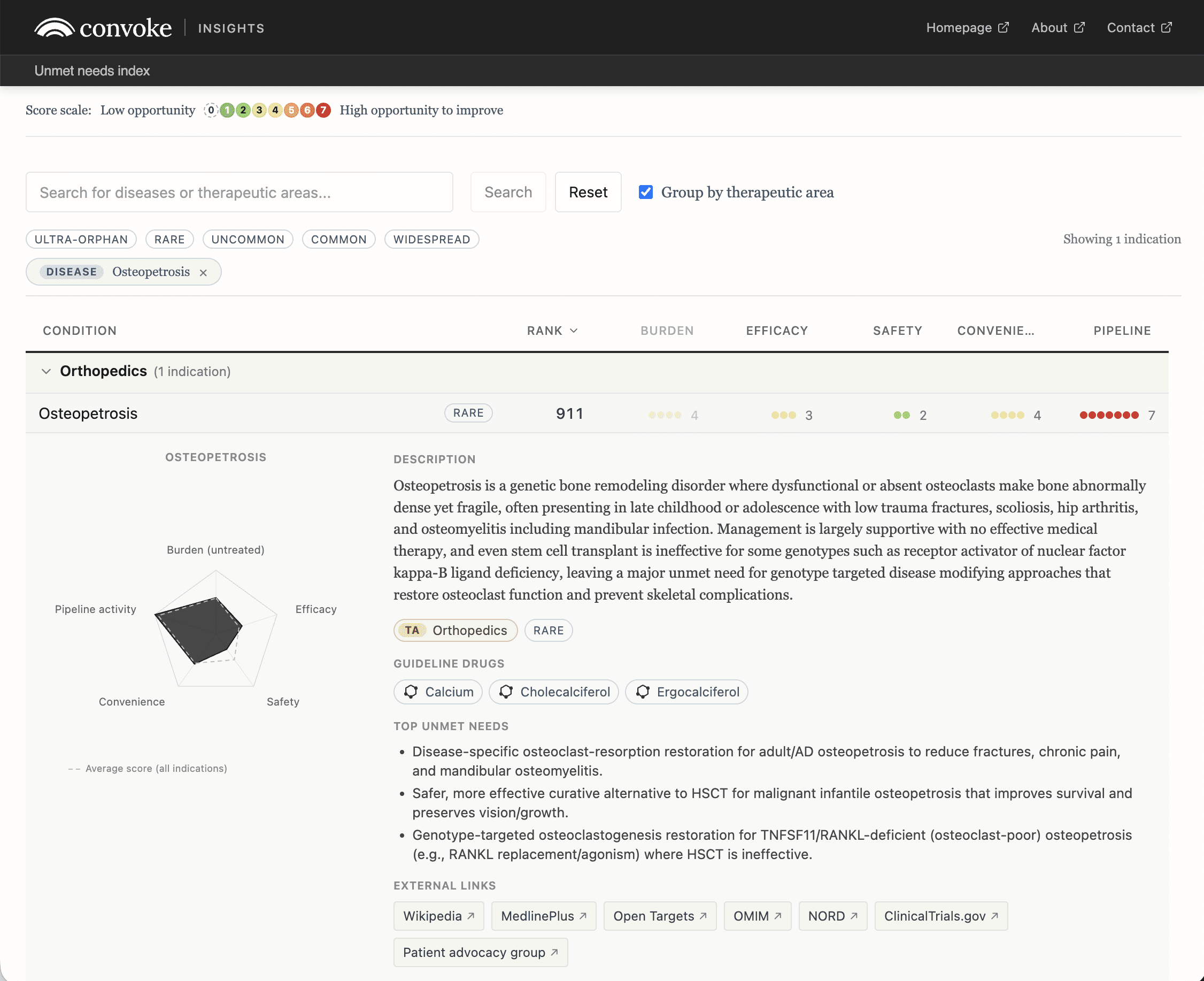
Convoke's Unmet Needs Index shows what this kind of platform can produce. The public resource scores and ranks 2,443 indications on burden of disease, prevalence, pipeline activity, and burden of treatment. Convoke describes the project as an attempt to "scan the entire corpus of human knowledge with the goal of surfacing overlooked information," with LLMs generating the underlying scores that feed a weighted composite. The index is a structured map of competitive landscape whitespace where disease burden is high relative to pipeline response, compiled at a scale no analyst team could assemble by hand.
Corporate BD and Asset Selection: What should we build, buy, or license?
As internal R&D has grown less reliable at filling pharma pipelines, BD has moved from a complement to R&D to the primary engine of growth at most large companies. EY's 2026 Firepower report found that global life sciences M&A investment rose 81% in 2025 to $240 billion, even as deal volume fell 12% and average deal size more than doubled, climbing 107% to $2.1 billion. In other words, companies today are paying more for fewer, higher-conviction assets. EY explicitly ties the acceleration to loss of exclusivity, growth gaps that are projected to reach $370 billion by 2032, and the imperative to capture "best-in-class innovation, wherever it emerges." That last phrase, "wherever it emerges," increasingly means China. In 2025, China captured 34% of US and European biopharma alliance investment, up from just 4% in 2020, and accounted for five of the ten highest-value alliance deals of the year; the total potential value of inbound China alliance investment has grown nearly elevenfold over five years.
Historically, biopharma BD has been sophisticated yet quite artisanal. Teams scout assets at conferences, monitor venture-backed biotechs, keep warm relationships with bankers, VCs, tech-transfer offices, and pharma BD teams; then assemble deal theses when something looks interesting. This process is relationship dependent and bandwidth constrained. A company may know the ten obvious assets in a crowded indication, but miss the abandoned Phase I program, the academic patent family no one has optioned yet, or the China-originated asset with best-in-class potential but limited Western visibility. Plainly speaking, current BD teams are both blind to a meaningful share of the deal universe and constrained, even on the assets they do see, on how thoroughly they can diligence them.
Agentic AI both quickens and deepens analysis while widening the aperture. Instead of waiting for inbound decks or semiannual partnering conferences, a BD agent can continuously scan trial registries, publications, patent filings, SEC disclosures, investor presentations, conference abstracts, financing activity, clinical readouts, and deal databases, then map opportunities against a company's actual strategic gaps. EY-Parthenon describes this as an "always-on biopharma deal radar," in which AI agents constantly read scientific papers, track clinical trial registries, monitor news feeds, query databases, and draft analyses tailored to a company's strategic interests.
Outlicensing is the inverse process. Rather than asking an agent to find assets, a biotech trying to partner an asset can ask an agent to find buyers. Analysts can map potential partners by pipeline gaps, recent clinical failures, patent expirations, prior deal behavior, therapeutic-area focus, commercial presence, and even by likely internal champions. The same machinery that scans for an acquirer can be pointed the other way to find an acquiree, and the same engine that powers competitive intelligence can drive asset search too: Convoke, the CI platform discussed above, positions itself as exactly this kind of horizontal layer, spanning competitive intelligence, business development, and portfolio strategy rather than any single bucket.
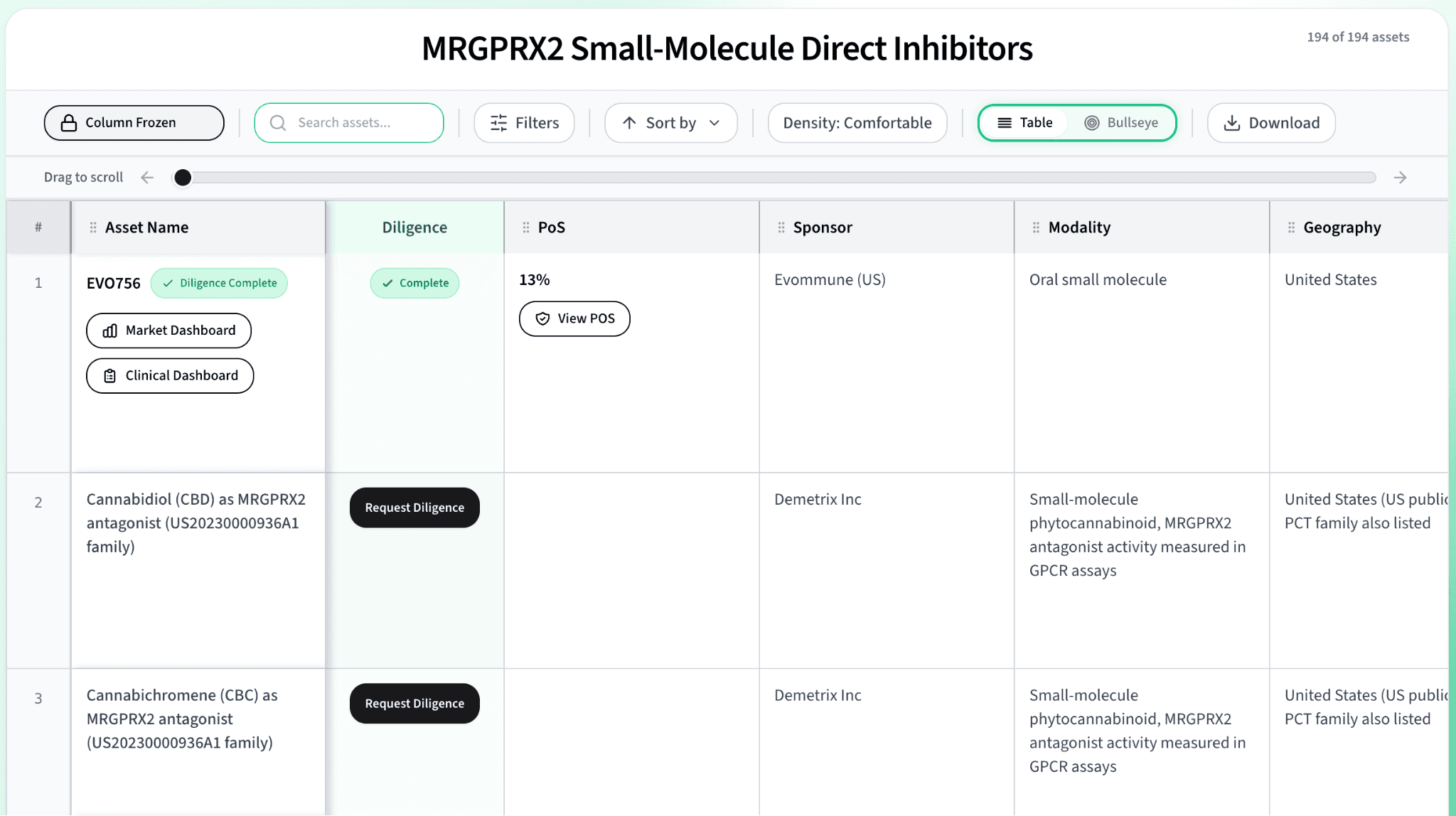
Convexia, a YC-backed company founded in 2025 by Stanford CS dropouts Ayaan Parikh and Rahul Vijayan, is an AI-native platform for sourcing, evaluating, and soon, developing drug assets. While their platform today spans many phases of the development lifecycle, most pertinent to this piece are three key parts: a Sourcing Agent that mines public and private databases and unstructured global data to surface overlooked preclinical candidates, from early-stage biotech programs to abandoned pharma IP; a Commercial Agent that analyzes FDA incentives, pricing dynamics, total addressable market, competitive landscape, and payer alignment; and a Probability of Success Agent that aggregates outputs from all other agents and benchmarks against analog deals using a proprietary scoring rubric developed with VCs, pharma, and KOLs. Importantly, Convexia isn’t trying to design new molecules; rather, unlike most AI-native pharmas, the scope of AI integration is largely strategic, sourcing and evaluating existing assets and using agentic analysis to determine whether the asset will be commercially viable.

NYC-based Formation Bio runs a buy-develop-sell model, using AI to identify "dark assets" other companies have quietly killed or de-prioritized, then advancing selected molecules in-house before licensing to pharma. The bet is showing early returns. In late 2022, Formation acquired gusacitinib, Asana BioSciences’ oral dual JAK/SYK inhibitor, and advanced it into Phase 3 for chronic hand eczema; three years after acquisition, the asset was sub-licensed to Sanofi for up to €545 million in upfront and milestone payments plus royalties. Sprifermin, a recombinant FGF-18 for osteoarthritis that Merck KGaA had carried through Phase 2 and effectively shelved, was outlicensed to Formation in January 2022 and is now being developed under Formation’s High Line Bio subsidiary. Both deals are mechanism-consistent with what the platform is designed to surface, though Formation has not publicly attributed either transaction to the tool specifically.
Beyond searching for what users input, a more interesting opportunity comes to mind when we consider the future of AI-driven BD. Today's BD agents respond to what a user types: "Find me Phase II autoimmune assets," "ADC companies in China," "the next GLP-1." Give an agent access to the company’s pipeline gaps, LOE exposure, commercial footprint, clinical-development capabilities, scientific priorities, deal history, and risk appetite, and could it autonomously determine what the company’s BD priorities should be in the first place?
Indication Selection: Where is our biology most likely to win?
A drug’s mechanism does not always map neatly to a single disease. In oncology, for example, one target expressed across tumor types can create a dozen possible development paths. The choice of lead indication can have enormous influence on clinical development costs, probability of regulatory success, and the commercial upside.
Historically, that choice has been one of the most consequential and least codified decisions in R&D. The process requires months of manual research: literature review, epidemiological analysis, competitive landscaping, KOL interviews, market sizing, and internal debate, usually summarized in a PowerPoint deck that reflects the judgment of a handful of senior leaders.
Over the past decade, specialized data platforms were built to aggregate the data needed for indication selection and commercial launches. Clinical trial and regulatory databases show what approaches have been tried in each indication and where failure modes emerge by line of therapy. Genomic repositories (TCGA, DepMap, the Cancer Cell Line Encyclopedia, UK Biobank) surface which patient populations actually express the target at clinically meaningful levels, what co-occurring mutations might predict response or resistance, and whether a biomarker-defined subpopulation could support a clinical trial. Electronic health records and real-world evidence (RWE) platforms (Flatiron, Komodo, Truveta) show how patients move through the actual care pathway: which subset is treatment-refractory, where outcomes drop off, and where physicians reach for off-label options because the on-label ones aren't working.
Creating these datasets required an immense amount of data engineering as well as human data labeling. Once this data was compiled, yet another layer of effort was required to create analyses and synthesize findings across sources into probability of success, commercial value per patient, and trial feasibility, weighing each input appropriately. AI lowers the cost of both layers. On the data side, extraction and labeling data are massively enhanced with large language models. On the analysis side, natural language interfaces make it easier to ask questions of the data, pull the right evidence, and compare candidate indications without requiring every question to become a bespoke data science project.
Indication selection sits on a spectrum of resolution. At one end is population scale observational data describing how patients move through care. At the other is high-resolution mechanistic analysis of which patients are most likely to respond.
The incumbent in population scale evidence is real-world data (RWD) aggregator Datavant. Its original product lines focus on privacy-preserving record linkage (PPRL) to tokenize and connect patient-level data across more than 350 data partners, 80,000 US hospitals and clinics, and the major EHR sources. This provides a longitudinal patient journey that can inform trial design, evidence generation, and launch strategy. The volume of clinical trials Datavant tokenizes has grown roughly 300% over the past two years as tokenized RWD has evolved from a regulatory submission supplement to an active input across strategy, development, and commercialization workflows. But this work has a ceiling: while observational data can show that patients on drug X have fewer later cases of disease Y, correlation isn't proof the drug caused the gap. Closing that gap drove the 2025 acquisition of Aetion, a real-world evidence (RWE) analytics firm whose products turn RWD into reproducible analyses and evidence generation.
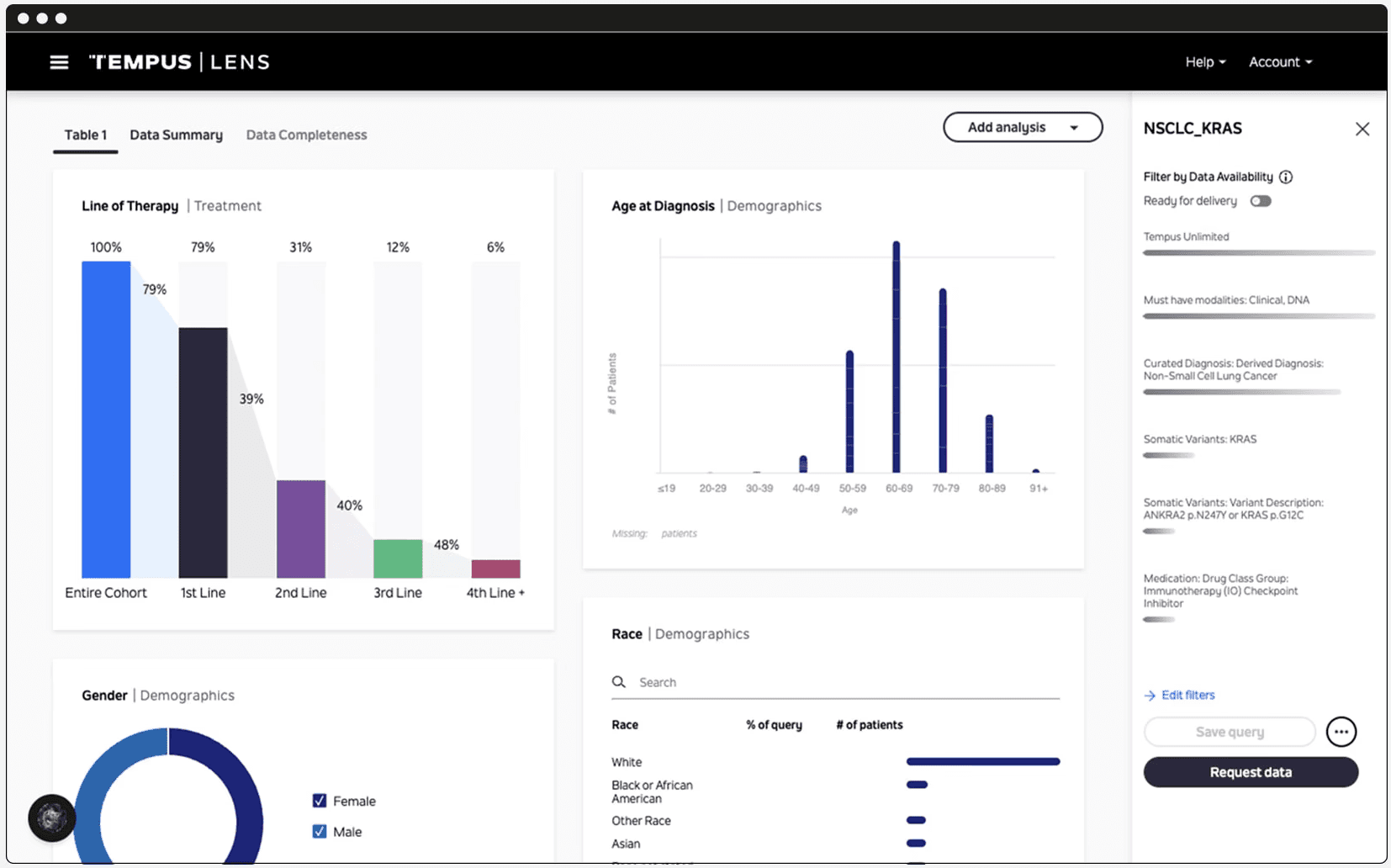
Tempus operates at the level of genetics and biomarkers. Best known for its work in clinical trial acceleration, the company describes its product as “the world’s largest library of clinical and molecular data” spanning multimodal sources: genomic sequencing, clinical outcomes, digital pathology, and RWE from electronic health records. Tempus helps its biopharma partners understand which tumor types and patient populations are most likely to benefit from a given therapeutic candidate.
In October 2025, Whitehawk Therapeutics partnered with Tempus specifically to inform indication prioritization across their ADC programs, using RNAseq to identify where its target proteins (PTK7, MUC16, SEZ6) are most strongly expressed in lung and gynecological cancers, and establishing whether RNA expression could replace IHC as the primary patient-identification method. Tempus reports that its engagements typically increase “probability of technical and regulatory success” (PTRS) by approximately 2% in the first year, growing to 7% by the second year. In an industry where Phase III trials can cost up to $55,716 per day, a few percentage points of PTRS improvement is formidable.
The implicit assumption in the 7% PTRS improvement claim is that “going narrow” is the right call. For most programs, it probably is, but it's worth noting this central tradeoff in indication selection strategy. A narrow, biomarker-defined population (say, HER2-low, PD-L1-high, KRAS G12C mutant) is enriched for responders, has a more favorable regulatory risk profile (the FDA tends to look favorably on biomarker-stratified trials), usually has a lower density of competitors, and makes Phases II/III cheaper and faster with a higher signal-to-noise ratio. But it simultaneously sets a ceiling on the addressable market and constrains the launch label. A broad indication (e.g., all patients with a given tumor type) has a much bigger commercial ceiling but is harder to power, more likely to fail on heterogeneity. Narrow indications can serve as a beachhead to get accelerated approval in a small high-unmet-need population, then expand the label outward (Keytruda is the canonical example, approved first in melanoma and now carrying 30+ indications), but the beachhead strategy depends on the science actually generalizing. The judgment call between narrow and broad still belongs to the CSO and development committee, but they now make it with higher-resolution data behind them.
Across all three layers, it’s becoming increasingly clear that an overlooked yet increasingly valuable use of AI in biopharma may not be in inventing molecules ex nihilo, but improving the quality of the strategic decisions that determine which molecules ever merit serious investment in the first place. The current universe of existing programs and assets is far more vast than human-bandwidth BD, CI, and indication teams can fully extract; AI's role is to close that gap. Competitive intelligence, indication selection, and asset selection all sit upstream of the clinic, but nonetheless govern an enormous share of downstream value creation or destruction. Before AI transforms how drugs are discovered, it may first transform the economics of deciding which drugs are worth building, buying, or backing at all.
Share this article