4 min read
For two decades, biopharma software organized what scientists produced but couldn't do science itself. That's starting to change.

Ashoka R.

Soleil W.

If you work in biopharma, you’ve certainly heard some version of the AI pitch before. A new technology has come to transform your workflow, compress timelines, cut costs, and transform R&D. Maybe you've looked on with skepticism: after all, the last generation of "transformative" software still left you doing most of the work yourself, just on a screen instead of on paper. But something about this time is different: the technology industry, an industry that famously characterized itself as the permanent ‘disrupter’ rather than the ‘disrupted,’ has found itself restructured from within, a shift with direct implications for the biotech industry.
The conventional technology diffusion story tells us that consumer and tech-native industries move first, while regulated industries, like healthcare and legal, follow years later, burdened by compliance overhead, liability exposure, and institutional conservatism. That pattern held for cloud, for SaaS, for mobile. But peculiarly, the AI wave has penetrated the most regulated, complex industries early on. More than half of the AmLaw 100 now rely on Harvey for support; the AMA found that 66% of U.S. physicians reported using healthcare AI in 2024, up from 38% in 2023. In other words, the technology became too useful for organizational inertia to ignore: law, medicine, and drug development are all language-dense, judgment-heavy, and dependent on synthesizing large quantities of heterogeneous information.
That inversion isn’t incidental. While earlier software could store information and move it around, it clearly couldn’t reason across information; frontier models (today’s most capable generative AI systems) increasingly can, and to a meaningful degree. The pre-2020 software wave was evolutionary rather than transformative; as useful as software was to organize what scientists produced, software itself could not conduct science.

Beyond increased efficiency of compute and inference, the ever-expanding context window (the amount of information a model can hold in working memory in a prompting session) has been instrumental in enabling improvement. In late 2023, the best AI models scored a measly 39% on GPQA Diamond, a benchmark of 198 PhD-level multiple-choice questions in biology, chemistry, and physics, where human domain experts score roughly 65%. Context windows hit their ceiling at around just 300 pages of text. As of early 2026, AI outperforms experts in expert-level scientific reasoning, and the context window has expanded to over one million tokens, capable of interpreting increasingly multimodal data. As any scientist knows, program decisions require triangulating across literature, assay outputs, study reports, protocol amendments, CRO deliverables, meeting notes, regulatory correspondence, and prior internal work, and AI excels at interrogating and synthesizing multimodal data.
To understand why the AI frontier represents a step-change in technological capability, it helps to understand what came before.

The first wave: digital foundations: The last two decades of software in biopharma were largely about moving from paper to the cloud. The focus was on data quality and compliance. This wave produced category-defining companies like Veeva, Medidata, Benchling, and Dotmatics. The alphabet soup of ELN, LIMS, LES, MES, QMS, EDC, CTMS, ETMF moved analog, paper-based data capture workflows to searchable, cloud-accessible systems of record, creating the digital layer on which most modern drug development now runs. But scientists were still responsible for the substantive work: literature review, data interpretation, writing conclusions, and making judgment calls.
The second wave: reasoning on demand. Large language models (LLMs) changed that. For the first time, software could read unstructured data, reason across it, and generate useful outputs, drafting text, summarizing literature, writing code, and interpreting experimental results. The Benchling 2026 Biotech AI Report finds that ~89% of scientists now use LLM copilots or reasoning tools. But LLMs are reactive: they produce an output when prompted and stop. The human still drives every step, deciding what to ask, evaluating the response, and determining what to do next.
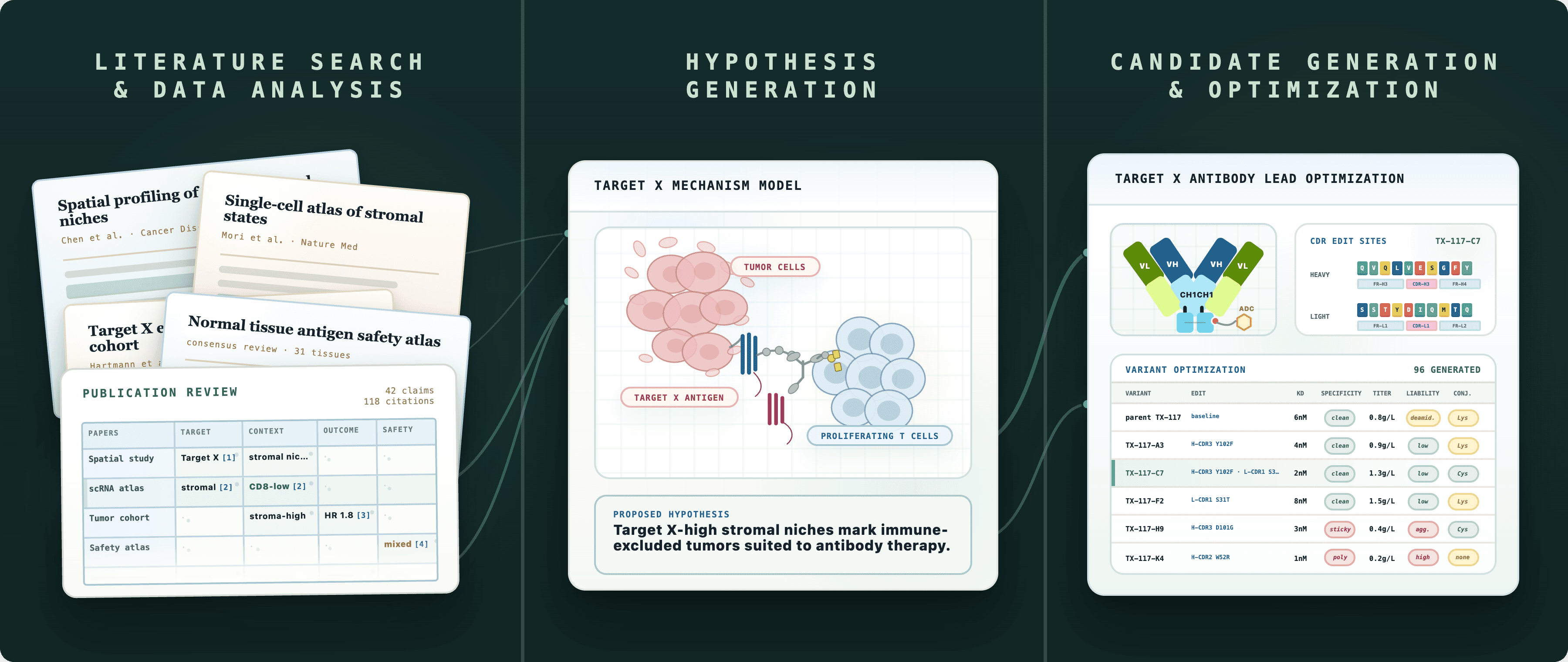
The third wave: delegating work. In this paradigm, the human’s role is to set the objective and review the outcome, while agents close the loop in between. In this series, we define agents as systems that operate in closed loops, autonomously executing multi-step tasks and self-correcting toward a defined goal, rather than producing open-ended output with no capacity to act on or iterate from that output. Importantly, while conventional automation follows predefined rules (if condition X is met, execute action Y), agentic AI generates its own action plan based on the goal it has been given, defining its own conditions for action when confronted with ambiguity. The system breaks a complex goal into executable steps, determines what data it needs, connects to databases, APIs, and external services without user input to acquire said relevant data, synthesizes it against your criteria, critiques its own output, iterates to improve it, and only upon self-review presents a recommendation. This approach also enables multi-agent architectures that mirror how organizations themselves work. Rather than route all information through a single system, each agent specializes in a different domain, connecting to different data sources and running in parallel rather than sequentially, so a hallucination in one domain doesn't corrupt reasoning in another.
In this series, we'll dive into this new division of labor in biopharma R&D created by the third wave, and what it means for how drugs actually get developed and into patients.
Agentic AI across R&D Functions
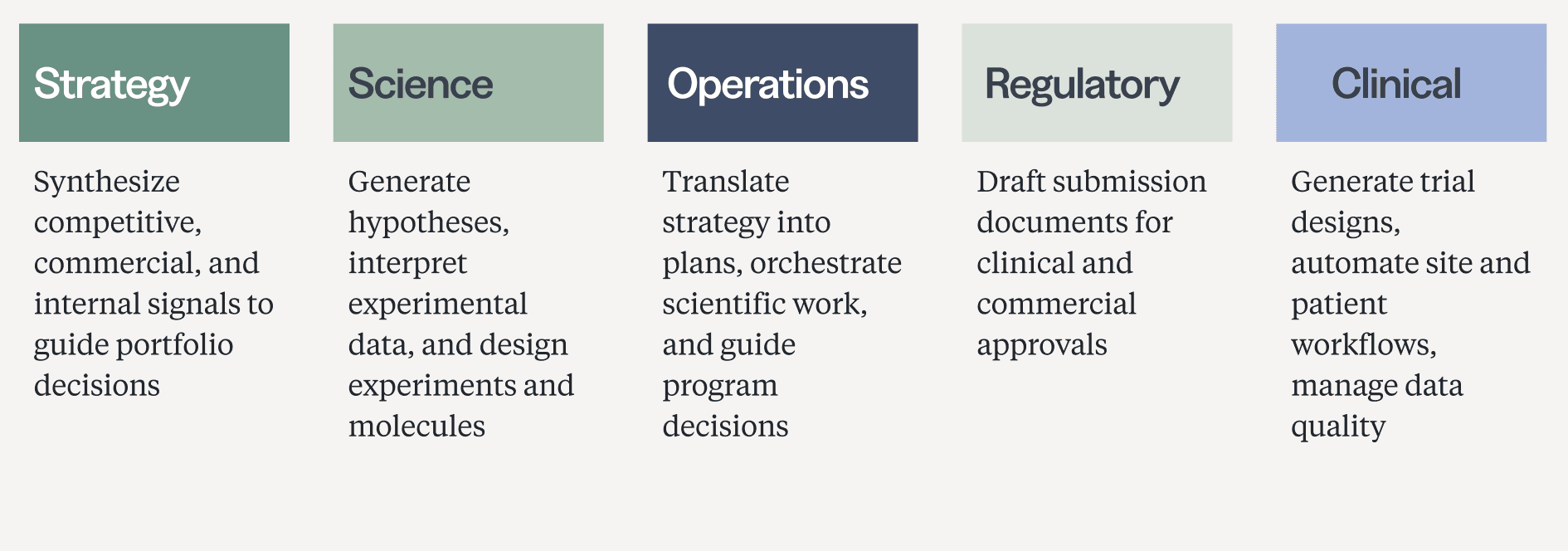
Why segment by function rather than R&D stage? The classic bucketing by R&D stage maps to how biopharma organizations manage the movement of a molecule through a pipeline, an organizational logic that also shaped the last generation of software. Tools were built for specific stages, handoffs, and systems of record, from ELNs in discovery to EDCs in clinical development. But agentic systems aren’t built around the R&D stage; they’re built around reusable units of work. A literature-search agent, once good at retrieving, ranking, and synthesizing evidence, isn’t limited to discovery. The same capability can support indication selection, clinical trial design, competitive intelligence, and more. This is another part of what makes the AI shift structurally different from the SaaS wave: while prior software was purpose-built for where work happened, agentic AI can generalize across contexts by mastering the underlying task.
The life sciences industry has quickly adopted chatbots, and they have made individuals more productive by shouldering the burden of text-heavy, low-risk work. But chatbots are fundamentally passive, requiring constant human intervention. The larger impact will come from agents that can take responsibility for recurring units of knowledge work, redirecting the role of the human from manual executor to workflow designer and reviewer, specifying what agents should accomplish, and making the difficult judgment calls that remain outside the scope of any agentic system. Over the next six pieces, we’ll trace where agents are starting to do that work across the biopharma industry, function by function.
Ashoka R.
Soleil W.
Share this article