12 min read
AI scientists are already delivering real productivity gains in discovery, but their lasting value will hinge on predictive validity.
On average, the process of bringing a drug from initial laboratory research to FDA approval requires 10 to 15 years and costs over $2 billion. More troublingly, those costs reflect a broader decline in pharmaceutical R&D productivity. In 2012, Jack Scannell and colleagues termed this trend Eroom’s Law: since 1950, the number of new drugs approved per inflation-adjusted billion dollars of R&D spending has roughly halved every nine years despite major advances in biology, chemistry, and computation. One instinctive response to these numbers is to cut the cost of clinical trials, where the vast majority of R&D spend occurs. But AI’s greatest potential leverage on R&D productivity may lie earlier, in discovery and preclinical development, where even modestly improving a candidate’s probability of success can prevent billions in wasted downstream investment. Per Scanell’s analysis, moving from 0.5 to 0.7 predictive validity preclinically could be worth hundreds of millions of dollars per Phase I candidate, not by reducing trial costs, but by ensuring fewer doomed molecules enter the clinic in the first place. The need for better early prediction is only becoming more acute as new drugs compete against an ever-improving, often cheap generic back catalog, and R&D gets pushed into harder diseases where old tools and models are less predictive. This is the promise of AI for scientific discovery: not only to accelerate existing workflows, but to improve the quality of the bets made before the most expensive experiments take place.
Pharma has taken notice of this thesis.Chai Discovery reached a$1.3 billion valuation eighteen months after incorporation. Isomorphic Labs has thus far raisedover $2 billion, supplementing nearly $3 billion in combined deal potential from partnerships with Eli Lilly and Novartis. Lilly committed up to$2.75 billion to Insilico Medicine for a portfolio of AI-designed oral therapeutics. Pfizer locked in a multi-year collaboration with Boltz to deploy their state-of-the-art biomolecular foundation models. And there are early signals that the bet is paying off. PitchBook has argued that AI could materially improve overall clinical success rates from about 7.9% to 17.7%, with the largest gains in early clinical phases. AI-native biotechs have so far achieved approximately 80 to 90% Phase I success rates compared to the industry average of 40 to 65%, and 40% in Phase II, versus a historical average of 29%, although the dataset remains small at roughly 10 completed trials. As of May 2025, no AI-generated drug has received FDA approval, though hundreds of AI-developed programs are currently in clinical development, with the first approvals projected for 2026 or 2027.

AI-native drug discovery is often discussed as one category, but companies in the space are making distinct claims. At one end sit systems that compress existing knowledge work such as literature review, data analysis, and evidence synthesis, increasing productivity. Generative R&D systems go one step further, ideating hypotheses or proposing protocols that may compress the time it takes to reach a validated R&D starting point. The most ambitious platforms bundle discovery and development, and their success isn’t measured by productivity gains or step-wise experimental validation, but by the clinical approval of their assets; in other words, these platforms rise or fall on predictive validity. Ultimately, even literature agents, candidate-generation models, automated experimental planners, and asset-building platforms shouldn’t be judged only by whether they accelerate existing tasks, but whether they improve the quality of selection: do they help scientists identify mechanisms, targets, molecules, or patient contexts that are more likely to survive human validation? If not, they may simply make the wrong pipeline move faster. Here, we map the landscape of AI-driven drug discovery: what current tools actually do, how they work at a level useful for decision-making, and where they fit into the broader role of AI integration in the biopharma industry.
1) Literature Search and Data Analysis

The clearest near-term win is AI applied to a specific problem: surfacing knowledge that already exists, either internally or externally, but that human-bandwidth search can’t reach. Elicit is a clear example: used by over 2 million researchers and serving customers including Formation Bio and Oxford PharmaGenesis (which advises 8 of the top 10 global pharma companies), the company uses AI to automate literature review: finding relevant papers, extracting their key findings, and organizing them into structured tables, matching on concepts rather than keywords so it surfaces work a term-based search would miss. The platform runs semantic search across over 138 million papers and in one third-party benchmark from VDI/VDE, correctly extracted 1,502 out of 1,511 data points across a systematic review, an accuracy rate of 99.4%.
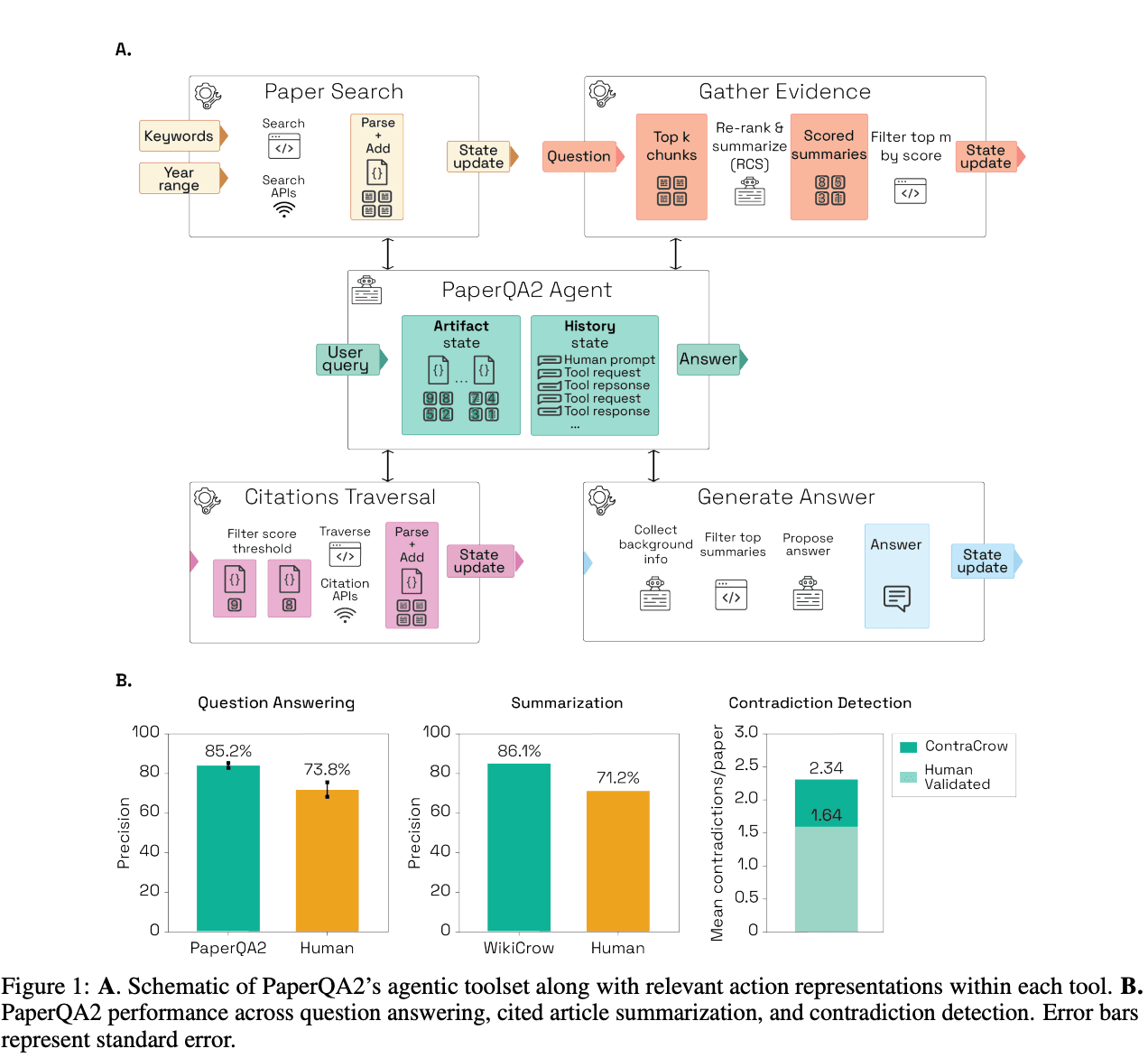
But pure literature search is only the first layer of the problem; the next step is an AI system that doesn’t just retrieve information from papers, but agentically keeps searching, checking, and revising as a scientist would, turning scattered insights into a live research process. In September 2024, FutureHouse launched PaperQA2, a literature-retrieval and synthesis agentic RAG system built to search papers, follow citations, extract evidence, and iteratively refine answers. Core to PaperQA2’s step-change improvement over previous models was its agentic nature: after a first round of search and evaluation, the model autonomously decides whether to run additional searches, reformulate the query, or revise the structure of its answer. PaperQA was rebranded as Crow in May 2025 and became just one cog in an open platform of specialized agents for distinct research tasks: Crow, Falcon, and Owl for literature search and synthesis, Phoenix for chemistry planning, and Finch for complex data analysis. On blinded benchmarks, PaperQA2 outperformed human PhD-level researchers on question answering (85.2% vs. 73.8% precision) and cited-article summarization (86.1% vs. 71.2%), and an extension called ContraCrow surfaced more contradictions per paper than human validators.
At the proprietary R&D scale, Benchling, the dominant R&D cloud platform used by over 1,300 biotechs and pharmas, has released a deep research agent that operates over Benchling data with the context of the Benchling data model. CEO Sajith Wickramasekara gives a specific example of how Benchling's agentic infrastructure saved one customer nearly eight months of work: a team preparing to run mouse studies across 20 models used the deep research agent to discover that a significant subset of those experiments had already been run years earlier by scientists at a company that had since been acquired. The discovery was possible because Benchling's data model preserves provenance across the acquired entity's historical experiments, which means knowledge that survived an M&A event but was no longer accessible to the surviving organization's institutional memory could be retrieved by the agent. Benchling is also integrating open-source and proprietary models (including Boltz, Chai, and AlphaFold) directly into scientific workflows, pre-configured so that wet lab scientists without computational skills can run simulations and have the results link automatically to their existing data. The longer-term aspiration is to move from passive simulation toward active recommendation: suggesting the next best experiment based on a scientist's historical work and the public literature. Its Experiment Optimization feature trains a “tournament” of ML models on a scientist's historical data to identify which input parameters most influence outcomes. The company is now tightening the integration between Experiment Optimization and study planning, and through a partnership with Stanford's Generative Expert Labs (GXL), is building domain-specific expert agents that reason across datasets and recommend model runs natively inside Benchling.
Beyond literature and proprietary R&D, the Stanford spinout Phylo raised $13.5 million in seed funding in February 2026, co-led by a16z and Menlo's Anthology Fund with Anthropic, to commercialize Biomni, the open-source biomedical agent already running in more than 7,000 labs. Its foundational “integrated biology environment,” Biomni-E1, wires together 150 specialized tools, 105 software packages, and 59 databases, so a scientist can run a multi-step analysis from one interface instead of hand-assembling a pipeline across a dozen. Phylo’s insight is that one of the highest friction chokepoints in data analysis isn’t in wrangling any single model but in stitching them together; Crow, Benchling, and Phylo are all different strategies for reasoning over three scales of unstructured information.
2) Hypothesis Generation

The most measurable gains so far come from AI applied to knowledge work that already has clear benchmarks: literature retrieval, evidence extraction, and data analysis. These are tasks where time savings and accuracy can be quantified relatively easily; a harder test for AI is whether an agent can propose a target, mechanism, or compound that wasn’t already flagged in the literature, then have that hypothesis validated. 2025 made clear how high that bar is. Sakana's AI Scientist was independently evaluated and found to misclassify established concepts as novel and produce hallucinated numerical results in four of seven manuscripts. When FutureHouse's Robin, a multi-agent system that orchestrates Crow, Falcon, and Finch, proposed ripasudil (a Japanese glaucoma drug) for dry age-related macular degeneration via a ROCK inhibition mechanism, it drew similar pushback; what Robin contributed was a specific drug-indication pairing rather than the underlying mechanism, a meaningful contribution but a more modest one than the initial framing suggested. While the speed and cost-efficiency of these tools is impressive, the ultimate test is whether the hypotheses produced are both original and verifiable.
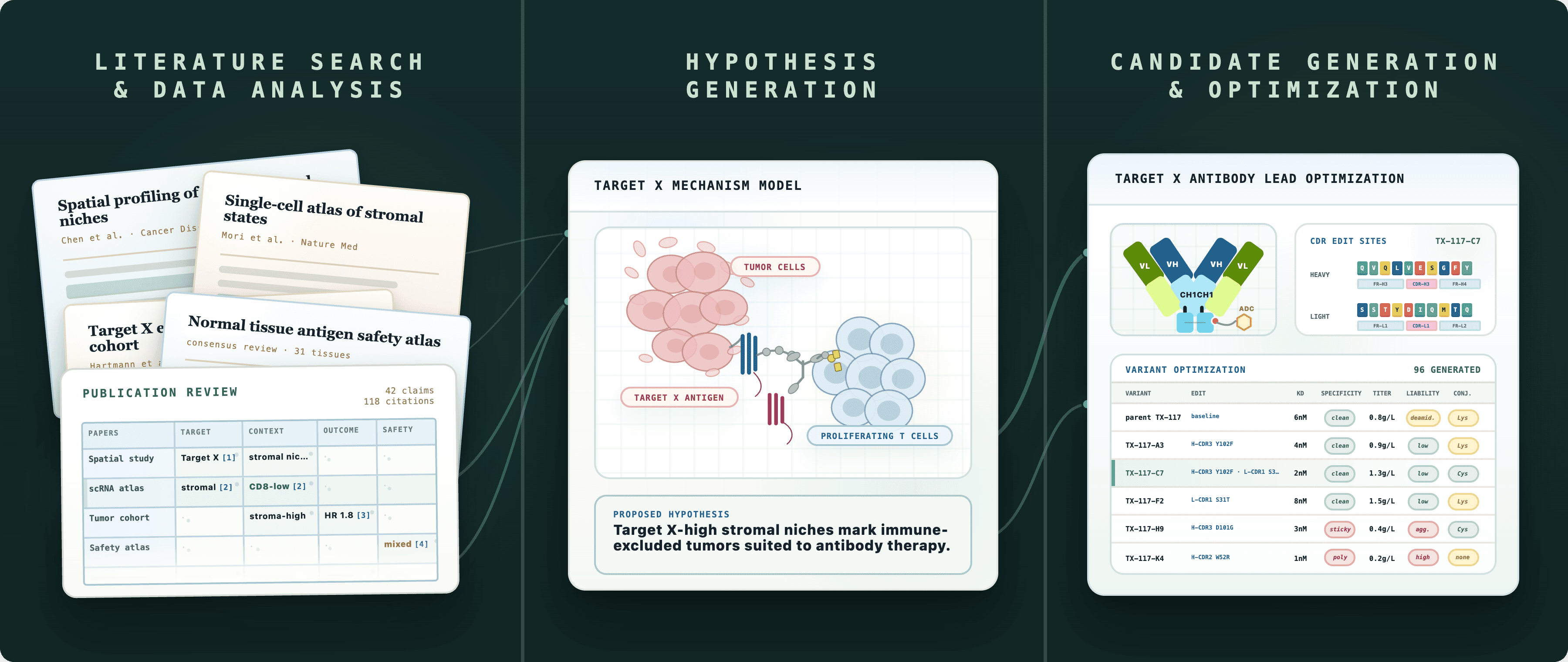
Another academic demonstration of the multi-agent thesis arrived in February 2026 from James Zou's group at Stanford: a preclinical discovery system organized around a virtual CSO that coordinates four scientific divisions (target identification, target safety, modality selection, and clinical operations) across eleven specialized agents and over one hundred tools through Model Context Protocol (MCP) endpoints. In one case study, the system was asked to evaluate B7-H3 as a therapeutic target in lung cancer. The statistical genetics agent found no significant germline associations but flagged regulatory activity at the locus, the single-cell atlas agent identified B7-H3 enrichment in cancer-associated fibroblasts, and the scientific reviewer agent found that ligand-receptor inferences lacked spatial context. That critique triggered a follow-up spatial transcriptomics analysis confirming immune-excluded niches around regions with high B7-H3 expression, after which a clinical trialist agent ran a biomarker-stratified survival analysis on a lung adenocarcinoma genome atlas (HR = 1.82 for disease-specific survival, p = 0.031). The virtual CSO ultimately recommended an antibody-drug conjugate modality, de-prioritizing small molecules and PROTACs after the pharmacologist agent found no druggable pockets.
While the truly “original” nature of AI-driven target discovery remains controversial, the FutureHouse and Zou group results nonetheless exemplify the architecture the field is converging on: lab-in-the-loop systems where agents own hypothesis generation, experiment design, and data interpretation, while human researchers set the problem, judge which AI outputs to pursue, and execute physical experiments. Beyond computer-based agents, a newer category of tools is moving into the physical lab itself: Seattle-based Potato.AI’s "Tater" co-scientist agent handles protocol design, literature synthesis, and analysis for researchers at Stanford, Scripps, and MIT, while a partnership with Ginkgo extends the platform toward assisting automated systems. Seed-stage startups like Ampliment are working to build a hands-free real-world interface for bench scientists, providing adaptive training and real-time guidance as researchers move through protocols. And moonshot full-stack lab automation platforms like Medra, which raised over $52M from partners like Lux Capital and Neo, are building physical AI to autonomously run experiments end-to-end.
3) Candidate Generation

Candidate generation is where AI stops reading about molecules and starts proposing them. The job is to pull molecule design out of the wet lab and into computation, compressing the design-build-test cycle and opening up targets that medicinal chemists had written off as undruggable. Technology isn’t new to this work; for decades, drug hunters have used software to sort through molecules, screening enormous virtual libraries against a target and algorithmically scoring which compounds were worth the cost of synthesis, formalizing the structure-activity patterns that good medicinal chemists carry in their heads. But the software could only choose among molecules that already existed, never invent a new one.
The integration of computation into drug discovery can be split into three eras:

While dozens of companies are competing in in generative design, two illustrate distinct approaches to generative drug design.
Boltz: The Open-Source Affinity Predictor
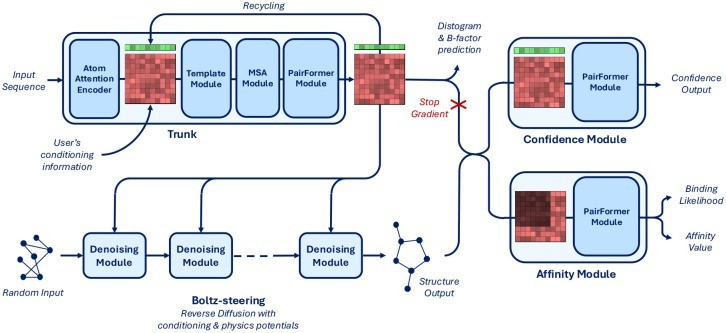
Boltz-2, developed by MIT Jameel Clinic alongside Recursion, is a biomolecular foundation model predicting how proteins, nucleic acids, and small molecules fold and assemble into 3D complexes; the model’s real breakthrough, however, was its ability to predict binding affinity, a measure of how tightly a candidate molecule attaches to its target. Before Boltz, if your discovery team wanted to computationally predict binding affinity, they had two options. They could use expensive, slow physics-based simulations called free-energy perturbation (FEP) that take hours to days per compound and require specialized computational chemistry expertise, or they could use faster but far less accurate AI models. Boltz-2 was the first deep learning model to approach FEP-level accuracy in binding affinity prediction while running roughly 1,000 times faster, approximately 18 to 20 seconds per prediction on a single GPU. Architecturally, Boltz-2 pairs diffusion-based molecular structure modeling with a dedicated affinity module trained on roughly 5 million experimental binding measurements, allowing it to predict both whether a molecule binds at all and how strongly it does. Boltz-2's training data is also multimodal, incorporating PDB structures, NMR data, and publicly available molecular dynamics simulations. Unlike Boltz-1, Boltz-2 also includes a layer called "Boltz-steering" that uses physics-based corrections at inference time to avoid proposing molecules that would physically crash into each other (steric clashes), a common failure mode for pure AI approaches.
Chai Discovery: Zero-Shot Antibody Design
Founded in 2024 by Joshua Meier (who co-led ESM-1 development at Meta FAIR and served as Chief AI Officer at Absci), Chai Discovery went from idea to $1.3 billion valuation by December 2025, barely 18 months after incorporation. Chai-1, launched in September 2024, was the company's breakout model, building on AlphaFold's core architecture with two notable additions: residue-level vector embeddings from a 3-billion-parameter protein language model, and a modular conditioning system that accepts experimental restraints (pocket conditioning, contact constraints, docking constraints). While early AlphaFold had to predict blindly, Chai-1 could be guided by what scientists already knew, like cross-linking data hinting that two residues sit close, or prior evidence of a binding pocket, letting the model update its prediction and shrink the search space. But it was still predicting structures, not designing them.
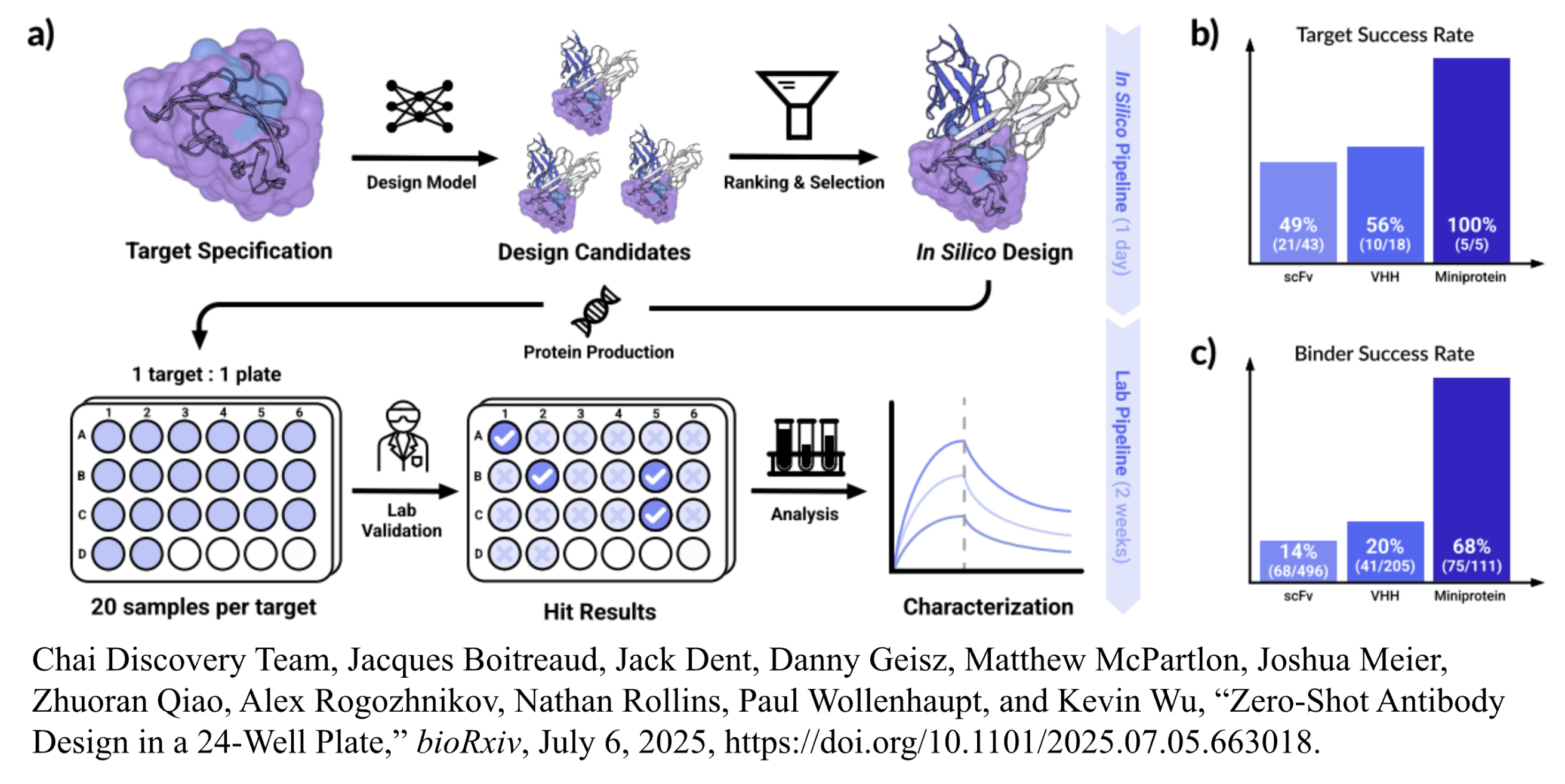
Chai-2, launched in June of 2025, was an inflection point for the company, as it moved from prediction to generative design. Chai-2 is an all-atom multimodal model, meaning it explicitly represents not just protein backbones but also side chains, ligands, and post-translational modifications, going beyond residue contacts to more closely mimic “real world” protein complexity. Instead of starting with antibody libraries or known binders, the model takes as input the antigen structure and the specific epitope region that should be targeted, then jointly generates antibody sequence and structure, particularly the complementarity-determining regions (CDRs) that form the binding interface. Across 52 novel targets with unknown binders, Chai-2 achieved a ~20% wet-lab hit rate for nanobodies, a striking 68% hit rate for miniprotein binders with picomolar affinities, and a 16% overall hit rate for fully de novo antibodies, a number described as over 100-fold better than prior baselines. Taking Chai’s claim of a >100-fold improvement over previous methods at face value, identifying 10 binders with Chai-2 requires generating and testing roughly 63 antibody designs; a baseline 100-fold worse would need on the order of 6,300 designs to get the same 10 hits. That implies roughly a 99% reduction in wet-lab constructs tested in this specific zero-shot antibody-design setting. The system even designed functional GPCR agonists, historically "undruggable" targets, for 2 of 6 tested cases. Cryo-EM validation showed sub-angstrom agreement between predicted and experimental structures. Commercially, Chai Discovery secured an Eli Lilly partnership (announced January 2026) described as "one of the pharma industry's largest AI software deals," involving deployment of the Chai platform plus a custom AI model trained on Lilly's proprietary data.
4) Candidate Optimization

Before a drug can demonstrate efficacy, it must first demonstrate stability and safety; a candidate that enters Phase I with an undetected liver toxicity signal or a hERG liability is a multi-million dollar mistake that better preclinical prediction could have prevented. But safety prediction is only half of the optimization challenge. The other half is lead optimization itself: taking an initial hit compound and systematically improving its potency, selectivity, stability, and manufacturability, all simultaneously, until it meets the stringent criteria for an Investigational New Drug (IND) application. Among the roughly 90% of drug candidates that fail in clinical development, analyses of trial outcomes from 2010 to 2017 attribute approximately 30% of failures to unmanageable toxicity and another 10–15% to poor drug-like properties.
An important caveat: the "before AI" baseline for optimization and safety prediction was never a blank slate. The biopharma industry has used computational and machine learning tools for ADMET assessment for decades. Medicinal chemists applied rule-based filters like Lipinski's Rule of Five and structural alerts for known toxicophores; legacy quantitative structure-activity relationship (QSAR) models from Lhasa Limited (Derek Nexus), Simulations Plus (ADMET Predictor), and others flagged obvious liabilities in silico before compounds were ever synthesized. For lead optimization specifically, tools like Schrödinger's FEP+ (free energy perturbation) have been used since the mid-2010s to predict relative binding affinities, allowing medicinal chemists to computationally triage which analogs to synthesize before committing to wet lab work. Nonetheless, these legacy tools operated within narrow domains and struggled in tasks requiring multi-objective optimization and in modeling the complex, non-additive interactions between mutations or structural modifications that determine whether a candidate molecule actually works in a living system. Today, frontier AI is able to navigate high-dimensional chemical space in a way these earlier tools could not, learning non-obvious patterns from sparse experimental data that no medicinal chemist could intuit.
Lead optimization

Where Chai and Boltz generate candidate molecules from scratch, Cradle occupies the adjacent and arguably more immediately practical problem of lead optimization. The Amsterdam and Zurich-based company's CRADLE-1 platform combines large-scale biological pretraining with customer-specific experimental data to guide protein and peptide design. Its models are trained on extensive protein sequence corpora and then conditioned on the evolutionary and functional context of a customer’s target family, allowing the system to efficiently navigate large combinatorial design spaces. As new wet-lab results become available, the platform updates its understanding of the underlying fitness landscape and proposes new candidates optimized across multiple properties simultaneously. Rather than relying on manually specified heuristics, Cradle helps scientists prioritize variants that are likely to satisfy complex design objectives while reducing the number of experimental cycles required to reach viable candidates.
In one case study, a top-20 pharma had three late-stage peptide programs that required simultaneous optimization of potency, specificity, expression, and thermostability within tight specification windows, and manual design exhausted all obvious sequence variants that could meet the necessary specifications. In a traditional sequential workflow, a chemist or engineer designs a library of potentially hundreds of variants, sends them to the lab, waits two to four weeks for assay data, discovers that most candidates fail on at least one property, tries to learn from the pattern of failures, designs a new library, and repeats for at least five rounds, requiring months of iteration. Cradle consumed all available sequence-function data from the partner's prior failed rounds, jointly modeled all four properties, and in just a single round, generated dozens of variants per program that met all four constraints simultaneously. Scientists remained responsible for defining project objectives, selecting relevant experimental inputs, and evaluating biological plausibility, while Cradle automated large-scale sequence prioritization across an otherwise intractable combinatorial search space.Notably, Cradle operates with a pure SaaS commercial model. Customers pay a software fee, keep the IP on whatever they design, and Cradle doesn't negotiate any royalties or revenue share. As CEO Stef van Grieken has stated, "AI in drug discovery and development will ultimately be a commodity, and any team should have access to it."
Safety and Pharmacology Prediction
Before turning to AI-native startups in computational pharmacology, it’s worth recognizing what an incumbent looks like. Certara’s Simcyp platform has spent more than two decades becoming embedded in pharmacokinetic, drug-drug interaction, and regulatory modeling workflows across pharma, and its D360 integrates assay data across ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity), efficacy, and selectivity for discovery teams. More importantly, Certara has built a regulatory moat: in 2026, the FDA accepted its PBPK modeling in place of ten dedicated clinical pharmacology studies supporting Novartis’s Scemblix NDA. As Certara layers AI into this established platform through Certara IQ and its acquisition of ChemAxon, newer ADMET companies must compete not only on predictive accuracy alone, but on workflow integration and regulatory trust.
Inductive Bio, a New York-based AI drug discovery company, represents the new generation of ADMET prediction built on large-scale consortium data and modern deep learning rather than expert rules or mechanistic simulation. Inductive's Beacon-1 models won both of the two largest blinded ADMET prediction competitions held to date: the Polaris Ligand ADMET challenge in 2025, and the OpenADMET-ExpansionRx challenge in February 2026. In January 2026, Inductive was awarded $21 million from ARPA-H (the Advanced Research Projects Agency for Health) to lead a multi-institutional team, alongside Amgen and several academic partners, in developing next-generation drug toxicity models that improve safety assessment and reduce reliance on animal testing. Architecturally, Beacon-1’s base model is pre-trained on the consortium data to learn shared representations of how chemical structure maps to ADMET endpoints (solubility, permeability, clearance, hERG, CYP inhibition, and so on), then fine-tuned to each partner's specific chemical space through proprietary transfer learning methods. Predictions come with probability estimates rather than binary pass/fail, enabling teams to assess risk on a spectrum, with millions of in silico experiments surfacing the strongest hypotheses for wet-lab validation. Unlike first-wave models, Inductive's Beacon models are differentiated in that they learn directly from experimental data at scale, with a continuous feedback loop from partner experiments that updates the models in real time.
Unlike Inductive, which applies a horizontal approach by aggregating and analyzing data from partners across the ADMET suite, Axiom Bio is currently going deep on a single problem: drug-induced liver injury (DILI). DILI drives roughly 20% of drug withdrawals and discontinuations, and contributed to failures ranging from major pharma programs like Pfizer’s danuglipron to clinical holds on gene therapies. To tackle that, co-founders Brandon White and Alex Beatson built Axiom around proprietary wet lab assays on primary human hepatocytes, paired with predictive models designed to help scientists make better late-preclinical decisions. The company eventually claims to have assembled the world’s largest human toxicity dataset, containing over 130,000 unique small molecules covering 1,200 targets and 50,000 scaffolds, including specialized classes of compounds like macrocycles, PROTACs, and molecular glues. Each well in Axiom’s assays measures 10 to 20 different cellular phenotypes related to toxicity, including apoptosis, necrosis, mitochondrial fission, ER stress, stress granule formation, microtubule stability, and then uses imaging and computer vision to process them. Altogether, the company has labeled more than 394 million individual cells and 9 billion mitochondria, which are then paired with a clinical dataset of over 5,200 documented DILI likelihood scores and more than 38,000 liver enzyme elevation data points, allowing Axiom to connect in vitro signals to clinical outcomes at a level of accuracy exceeding the performance of major pharma companies. Rather than handing customers a standard CRO-style data package and leaving them to sort through it, Axiom aims to deliver customers the synthesis on top of the data, owning the interpretation layer. The model works: Axiom is currently working with several top twenty pharma companies.
It’s worth noting one larger trend: the blurring of the line between “safety prediction” and “molecule design,” two different parts of the discovery stack. As generative chemistry platforms begin to incorporate ADMET considerations into their generation loops, the classic stepwise workflow of designing a molecule and then checking if it’s safe is being rolled into a single step. For example, Insilico’s Chemistry42 platform, a true-to-its-name orchestra of 42 distinct generative models (variational autoencoders, generative adversarial networks, transformers, normalizing flows, and RL policies) coordinated by a multi-agent reinforcement learning loop, incorporates ADMET filtering into its generative pipeline; the molecules that come out of the platform have already been filtered for predicted liabilities like toxicity, metabolic stability, and solubility before they ever reach the chemist. The question, then, for pure-play ADMET startups is whether they maintain value as a standalone step or are absorbed into the platforms that actually design the molecules themselves.
5) The Full-Stack Pharma

True platform efforts (reusable technologies that can generate or improve drug candidates across multiple targets, programs, or modalities) are rare because their value is proven only when the same underlying engine repeatedly produces clinically meaningful medicines, and the precedents predate AI. Regeneron's VelocImmune, the genetically humanized mouse platform that George Yancopoulos and Frederick Alt first envisioned in 1985, has produced seven FDA-approved fully human monoclonal antibodies. Alnylam spent roughly sixteen years and $2.3 billion translating RNA interference into a clinical platform before Onpattro became the first approved RNAi drug in 2018. Both cleared the ultimate bar of real approvals and durable licensing revenue, and AI full-stack players will be measured against that standard rather than against benchmark hit rates.
The most ambitious players run AI across the full sequence, from target to candidate to optimized lead, and then capture the value by developing owned therapeutic assets rather than selling the software that produced them. One advantage they are betting on is data: models trained on broadly available public datasets are replicable, but experimental systems that can generate human-relevant data (either internally or through partnerships) and feed it back into the model create a compounding moat. Thus, the most defensible platforms may be those that turn prediction into a proprietary data flywheel: using each experimental result to improve the model, and each improved model to generate more valuable biological evidence. The economics follow from the science: because building the experimental infrastructure and generating the datasets required to close that loop is enormously capital-intensive, companies building such platforms are strongly incentivized to capture value through owned drug programs or asset-linked economics, rather than software revenue alone.
Isomorphic Labs is a revealing test case for this thesis; the 2021 DeepMind spinout led by Nobel laureate Demis Hassabis has since grown to over 200 employees. Isomorphic was built on the AlphaFold lineage, each generation of which expanded the boundary of what AI could do for biology. AlphaFold2 (2020) predicted what proteins look like; AlphaFold3 (May 2024) predicted how they interact with other molecules; AlphaProteo (September 2024) generated new binding proteins (achieving 3-300× better binding affinities than existing methods across 7 targets, including the first-ever AI-designed binder for VEGF-A). On February 10th, 2026, Hassabis’s team published IsoDDE (Isomorphic Drug Design Engine), a unified computational system that moves decisively beyond AlphaFold3 into end-to-end drug design. Isomorphic claims that IsoDDE “more than doubles” AlphaFold 3’s accuracy on the ‘Runs N' Poses' benchmark (Škrinjar et al. 2025), created to determine a model’s ability to generalize past its training data to novel pockets and ligands. On antibody-antigen structure prediction, one of the hardest challenges in computational biology because of the flexible, hypervariable CDR-H3 loop, IsoDDE reportedly outperforms AlphaFold3 by 2.3x and Boltz-2 by 19.8x (notably, Boltz is a model optimized for small-molecule affinity rather than antibody structure, but the comparison is nonetheless impressive).
Drug discovery companies, when their tooling actually works, generally converge on the biopharma model rather than the platform model for the simple reason that a single internally developed drug captures far more value than a licensing platform. Nimbus Therapeutics, founded in 2009 on Schrödinger's free-energy perturbation methods, ran this playbook for over a decade before selling its TYK2 program to Takeda in 2022 for $4 billion upfront and up to $2 billion in milestones. Companies like Adimab work at both ends of the curve: on one side, "Funded Discovery" projects where the partner sends a target and Adimab returns leads in exchange for modest upfront fees, R&D funding, clinical milestones, and royalties on whatever eventually reaches the market; on the other, "Platform Transfer" agreements with GSK (2013), Takeda (2019), and four others (Lilly, Biogen, Novo Nordisk, Merck) in which the partner pays a large upfront fee plus annual licenses to install Adimab's yeast-display technology in its own labs and keep more of the eventual asset. On the opposite end, companies like Boltz operate as a pure software and infrastructure provider; customers pay for access to the Boltz Lab platform, retain ownership of whatever they design, and even the company's multi-year Pfizer collaboration is structured around building exclusive foundation models rather than co-owning therapeutics, with Pfizer keeping the compounds. CEO Gabriele Corso has also framed Boltz's open-source orientation as a cultural inheritance from MIT CSAIL, where "patenting is rare and research is typically shared openly."
For Isomorphic, AlphaFold plays the structural-prediction role that Schrödinger's FEP played for Nimbus, with proprietary chemistry, potency, and ADMET layers built on top. Its pipeline is currently focused on small molecules, with CEO Hassabis indicating in early 2026 that the company expects its first AI-designed drugs to enter clinical trials by the end of the year. Chai Discovery and Boltz are the genuine anomalies in this landscape; rather than converting their structure prediction capabilities into a biopharma pipeline, both have thus far positioned themselves as platform-and-foundation-model companies.
Huge Promises, Higher Bar
2024-2026 marked an inflection point for AI in drug discovery, moving the technology from analytical tool to generative engine. Three developments characterize this shift. First came AI-enabled compression of knowledge work, turning weeks of literature review, evidence extraction, and data analysis into minutes. Second was the architectural stacking of diffusion models, transformers, and graph neural networks into sequential foundation models that reach state-of-the-art performance on proteins, small molecules, DNA, RNA, and their interactions, all within a single model. The performance of these models is improving exponentially: hit rates have climbed from the mid-teens to the high double digits on some of the hardest-to-drug target classes, and the first AI-originated molecules are now advancing into mid-stage trials. And third was the arrival of end-to-end systems that fold the formerly serial, human steps of drug discovery into continuous computational loops; as is becoming increasingly clear, durable advantage accrues to the companies that own the assets these loops produce rather than the tools.
Importantly, questions and doubts about the future of AI-led discovery remain. No AI-discovered drug has received FDA approval, and there is still an unresolved tension regarding open-source democratization (Boltz, RFdiffusion, BindCraft) versus proprietary value capture (Isomorphic, Insilico, Insitro). The productivity gains are enormous, but only time will answer the ultimate question of whether AI can produce better drugs, not just quicker Phase I-ready assets.
Share this article

